
Awarding the amazing autosegmentation work from 2024
Automated scroll segmentation is coming

To close out the 2024 year-end prize series, we were thrilled to receive two fantastic submissions for the First Automated Segmentation Prize (FASP). Though they did not meet the full prize criteria - we’ll discuss below! - we’re incredibly excited about them, not only as standalone contributions but for the way they complement each other and illuminate the path forward.
For these achievements, we are awarding each submission with a Gold Aureus Prize++ of $30,000. Each individual on these teams will also receive a custom Villa dei Papiri set made from LEGO® bricks! We’ve been waiting for so long to share these!!!








The First Automated Segmentation Prize
The goal of the First Automated Segmentation Prize was to reproduce the segmentation behind the 2023 Grand Prize result, but faster. Instead of the hundreds of hours it took to manually annotate the Grand Prize region, we want an automated method that can do it with just four hours of human input. We predict this will allow us to scale the method so that it can feasibly be applied to the full collection of scrolls.
The full Prize required not only that the solution use less than four hours of human input (and 48 hours of compute), but that the resultant ink recovery was comparable to the 2023 result and that the mesh covered 95% of the 2023 mesh. Unfortunately, an anonymized and independent papyrological review found that neither submission quite recovers a comparable amount of text as the 2023 result. However, you’ll see that we’re getting so close, and that there’s a lot of momentum in the right direction - making it clear that these works are highly deserving of this prize award!



Let's take a look at each submission and see why we're so excited about them. Click through for more details - they're well worth the read!
Submission 1: Hendrik Schilling and Sean Johnson
If you’ve been following along at all, you will not be surprised to see a continuation of excellent work from Hendrik Schilling and Sean Johnson!
The submission has a number of contributions, but centers around two pillars: volumetric segmentation, and subsequent surface tracing.
Volumetric segmentation
The raw image data presents a number of challenges: noise, compressed regions with unclear sheet separation, and so on. Building a papyrus sheet out of this representation is tough, and common image operations don’t always help much (see below).
Instead, this submission invested heavily in training segmentation models that generate more structured data representations. These representations are more readily usable for the downstream tasks of tracing or assembling papyrus sheets with the data. Look at how much cleaner the segmentation output is than the raw data!


Doing this work involved not only technical contributions to model architectures and training, but also tremendous grit and determination. Many hours were spent refining training labels for the segmentation models until they could achieve this output. The submission includes a great writeup on this process!
Surface tracing
Once a segmentation model has produced a volumetric surface prediction, one must trace this surface into a sheet that can be flattened.
This submission uses the surface predictions to seed and then expand a set of surface patches - small pieces of mesh surfaces that locally fit to the papyrus.

Then, an iterative process traces a consensus surface by stitching adjacent patches together, allowing the user during this process to guide the tracing by annotating the patches as approved/defective or by editing them. Subsequent steps further fuse the traces, perform inpainting where the surface has holes, and render the surface into layers so ink detection can be performed.
The result is a contiguous mesh covering the region of interest, in this case the same region from the 2023 Grand Prize:

Though not yet perfect, it clearly follows the general structure of the scroll, and where it performs well, the segmentation precision exceeds what we’re used to, providing a glimpse into how great segmentation is bound to become. A mesh comparison with the GP mesh shows that it achieves broad coverage, and ink detection, though not quite there yet, is obviously capturing the same rough columns.

There’s so much more great information than we can cover here. Take a look at the full submission to learn much more about this method! We’re thrilled with the outcome: using just a few hours of human annotation time, we are close to being able to reproduce work that one year ago took hundreds or thousands of hours to produce.
Submission 2: Paul Henderson
The second FASP submission (code, writeup) comes from a relative newcomer to Vesuvius Challenge, who we are so grateful to have now in the community! Welcome, and thank you, to Paul Henderson!! We love this approach. Check this out.
Paul’s approach actually starts by building on part of Hendrik and Sean’s submission (we love this too) - it uses the outputs of their segmentation models as its initial inputs.
From there, a spiral is deformed to fit the data. Globally! Across the entire scroll! All at once!
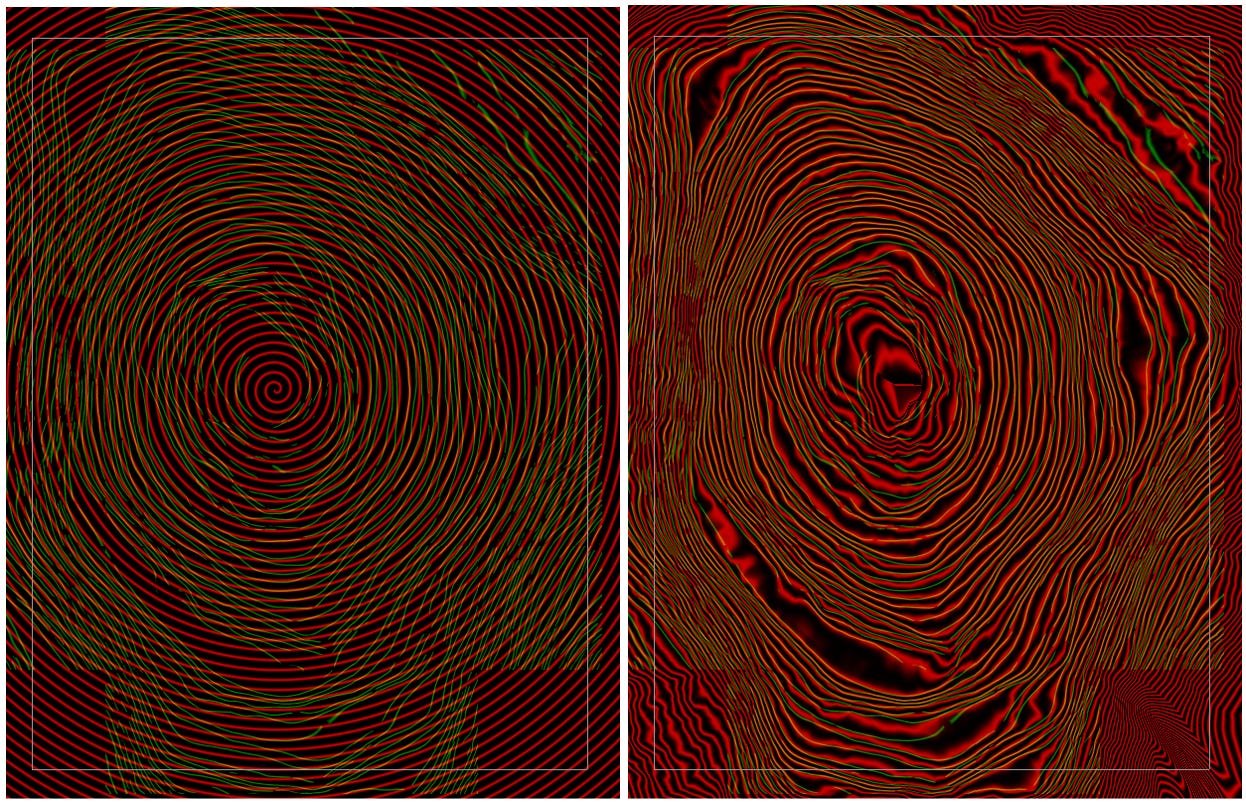
The method assumes that the scroll was once a single, flat sheet, and finds the deformation that fits this sheet to the data while preserving its topological integrity. The optimization parameterizes the deformation as a diffeomorphism, i.e. a smooth one-to-one mapping between the flattened sheet and the deformed one that fits the scroll.
There are elegant losses incorporated into the optimization, for example that in the canonical space, horizontal fibers should have a constant z coordinate and vertical fibers should have a constant theta coordinate (among others).

There are additional regularization terms that ensure the papyrus surface does not stretch and that the umbilicus is not pulled out of place during the fit.
We love the elegance of this solution, which represents the first serious segmentation result from a global optimization over the entire scroll. The codebase is small and computationally efficient relative to many of the bottom-up methods, and should provide a fruitful environment for experimentation and further progress.
As with the other submission, please do check out Paul’s excellent writeup and the associated code.
Hendrik, Sean, and Paul: start clearing space for your Villa dei Papiri models!
The Path Forward
In 2023, we took existing solutions for segmentation and turbocharged them: better and faster tools, optimized algorithms, and more humans. The results blew us away, but the methods had already started to run up against their limitations. We knew we would need a new approach to tackle a complete scroll and then an entire library.
2024 has been a collective journey of discovering the direction that path would take. Through contributions large and small, we’ve shined light on a number of potential avenues. Though there are still steps to be taken, we’re delighted right now that we can see the finish line and a path to get there!
The conceptualization of we call “segmentation” - the overarching goal of tracing the shape of the papyrus sheets inside the scroll scan - has progressed significantly. Before, we largely worked with raw image data, directly creating the segments that yielded text.
Now, this has been nicely divided into more separable subproblems. Representation focuses on extracting meaningful structure from the raw image data. This typically uses volumetric segmentation models to produce predictions of surfaces or papyrus fibers. Fitting then uses optimization and computational geometry to fit larger sheets to the structured representation. The two submissions above illustrate this beautifully. We believe that independent contributions can be made towards either subproblem, each resulting in improvements to the downstream objective: recovering lost texts from the ancient world.
Closing thoughts
There’s still work to be done! Ink detection is not solved yet for all scrolls: despite multiple legitimate submissions for the First Letters and First Title prizes, we still have not been able to conclusively recover text from Scrolls 2, 3, or 4 - those prizes went unclaimed in 2024.
As a natural extension of that result combined with the FASP results, the 2024 Grand Prize also went unclaimed. We’ll work to re-baseline the community and define a new set of objectives for the next stage of Vesuvius Challenge. We can’t overstate how excited we are about the current momentum!
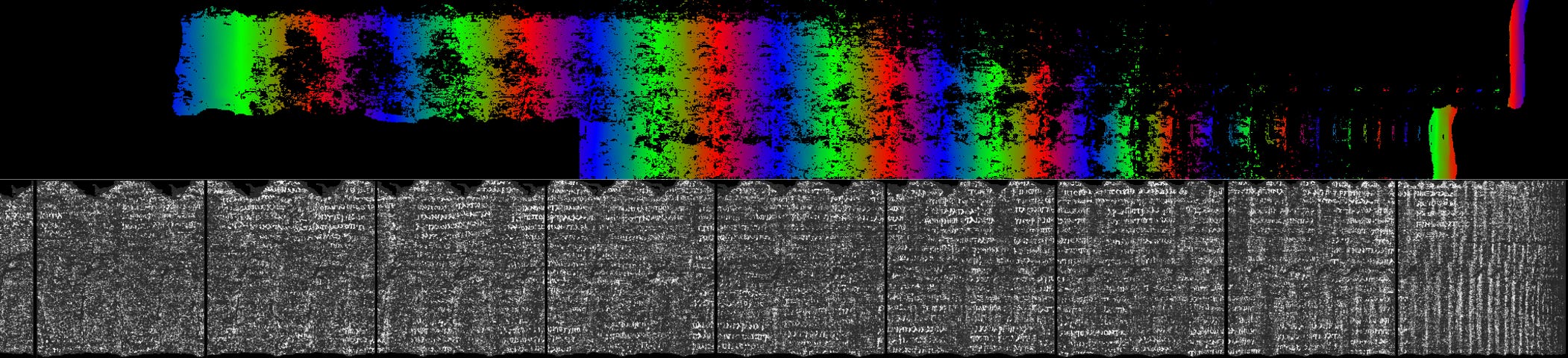
Building on the communal progress, our segmentation team is hard at work on some new annotations. Our goal is to get deeper into the more compressed scroll regions, providing structure where we’ve had none. Here’s a preview (more soon!):
There’s a LOT more in the works, too - we can’t wait to take you with us on this adventure.
Thank you, as always, to our community, team members, and partners - it’s a privilege to work on this project with you all. Onward and upward!
And remember: we’re hiring! Tell your friends 😁
I want the Lego Villa in my house!!
Are you planning to scan more scrolls in the short term? Just curious since some seem to possibly be "easier" to read than others.