
We are cooking
A list of updates from the Vesuvius Challenge


How has the Vesuvius Challenge been going in recent months?
We have many updates to share!
Agents and models
Autoresearch
Inspired by this repository, Youssef set up a swarm of automated agents that perform research on ink detection model architectures and training.
We currently have 4 agents working, and the results are very promising.
For instance, an agent whose goal is cross-scroll ink detection generalization managed to almost double the validation Dice score on PHerc. 1667 (Scroll 4) while training only on PHerc. 139 data.
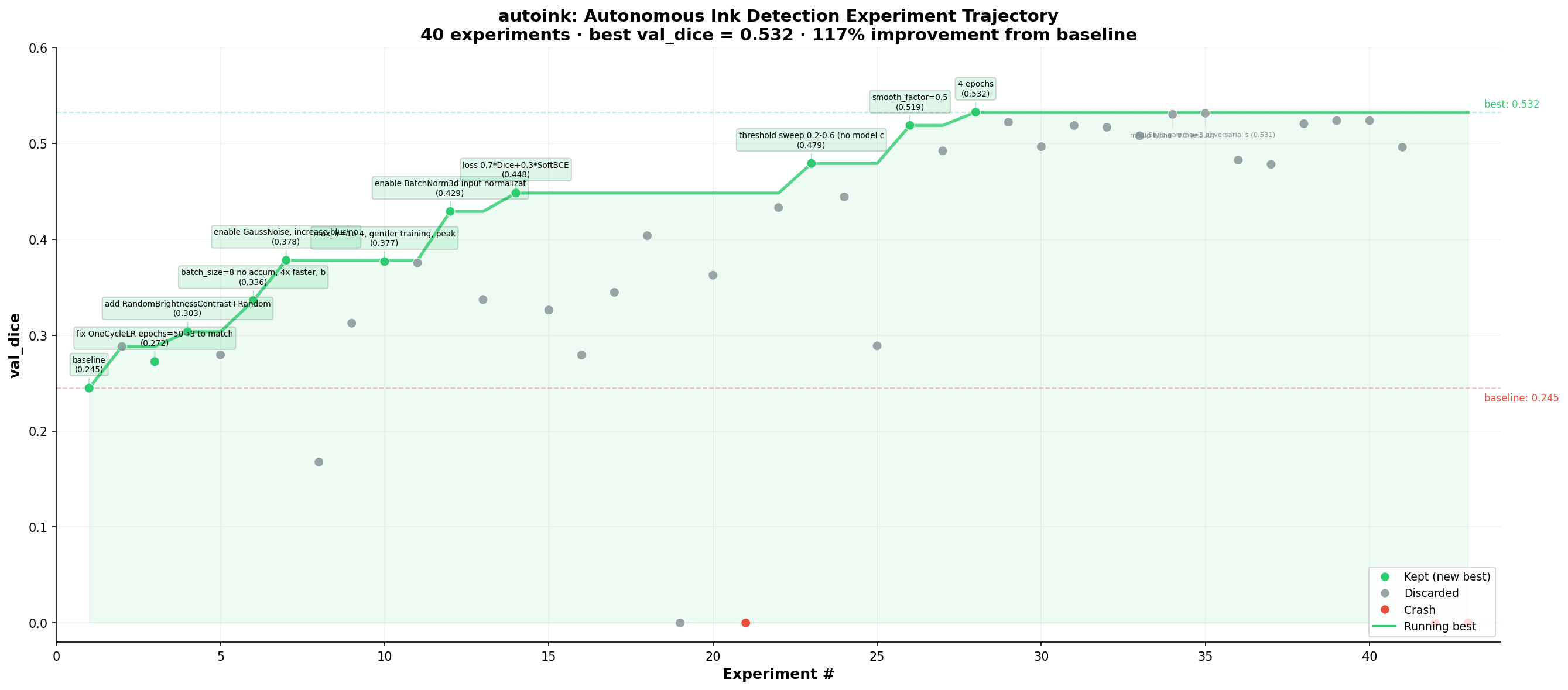
We currently have 4 agents working 24/7, and the results are very exciting.
Foundation models
We have scanned so many scrolls, we believe we have the largest high-resolution dataset in the world. It’s about time to train a scroll foundation model. Sean has adapted DINO from Meta to work on full volumetric images.

Training is currently underway on our cluster, but the learned features are already producing good-looking images.

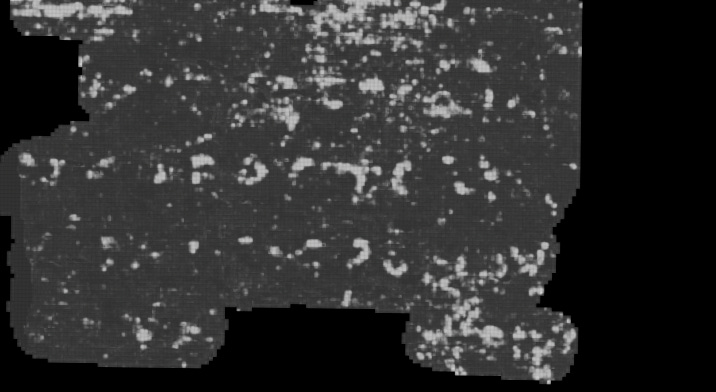
3D Ink
The team started to detach from the paradigm of detecting ink in a surface volume (a flattened portion of volume around a sheet).
Taking over the amazing work done by Ryan Chesler in 2024, we trained for PHerc. 172 (Scroll 5) an ink detection model that works directly on the unflattened volume scroll. This model is on-par with the 2.5D (surface volume based) ink of detection, the state of the art.
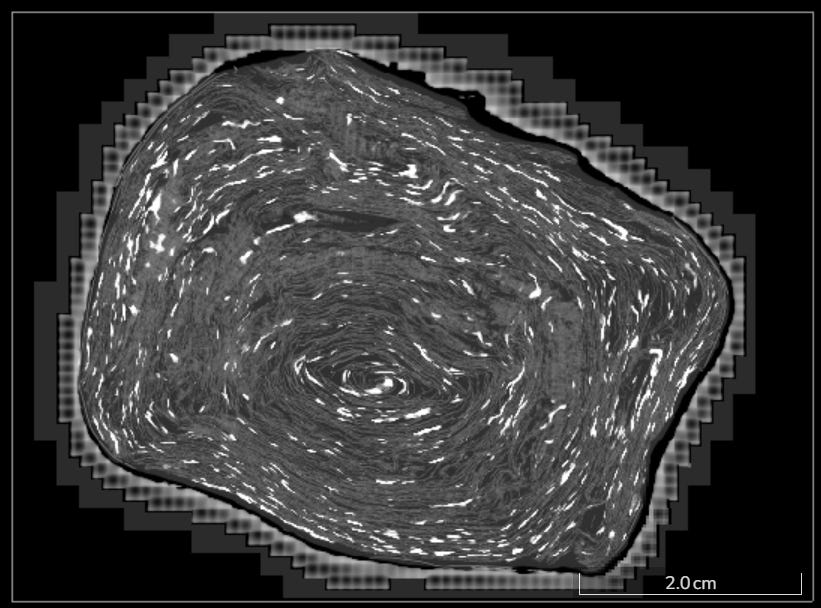
From the previous image it is clear that the outer parts of the scroll are the ones richer in ink detection predictions, while the core exhibits lower legibility (at least according to this model’s predictions).
While reading the text (and label production) can be done only in the flattened view, in principle one could load the 3D ink volume directly in VC3D and segment directly the parts with a good legibility.
We imagine that 3D ink detection will, at some point, become the baseline for future ink detection work.
Surface Detection — Kaggle competition
The $ 200K Kaggle competition for topologically accurate Surface Detection has ended! Eternal glory to the winners!
On the winning team is Paul Geiger, a familiar face in the Vesuvius Challenge community, who also won several progress prizes in the past!
Almost all of the top 10 submissions used large ensembles of our baseline, a ResEncUNet trained with the nn-UNet framework.
However, the Kaggle experts found multiple interesting training recipes, such as training for more than 4,000 epochs. They also addressed the problem of holes in the predictions with creative post-processing schemes.
The following is a visualization of how our baseline and one of the best Kaggle submissions performed in compressed regions, the hardest to virtually unwrap.
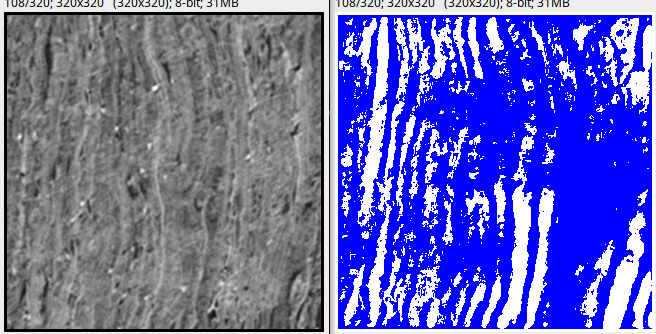
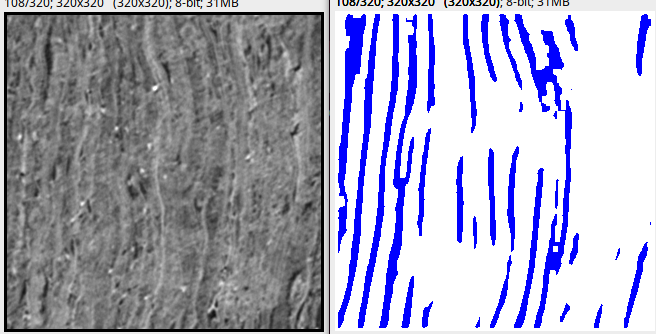
Much cleaner! While aggressive post-processing might seem to delete portions of sheets, this is much easier to handle in VC3D than big blobs in the predictions.
We are going to retrain models using a combination of the best shared techniques, but this time on our 2.4 um high resolution dataset! We are confident that the results along the way will speed up virtual unwrapping of the collection!
VC3D
Our semi-automated virtual unwrapping pipeline received several massive updates!
Streaming
Thanks to Forrest, VC3D now supports streaming remote scroll volumes and folders in volpkg format. You will no longer have to download TB-sized volumes to unwrap the scrolls!
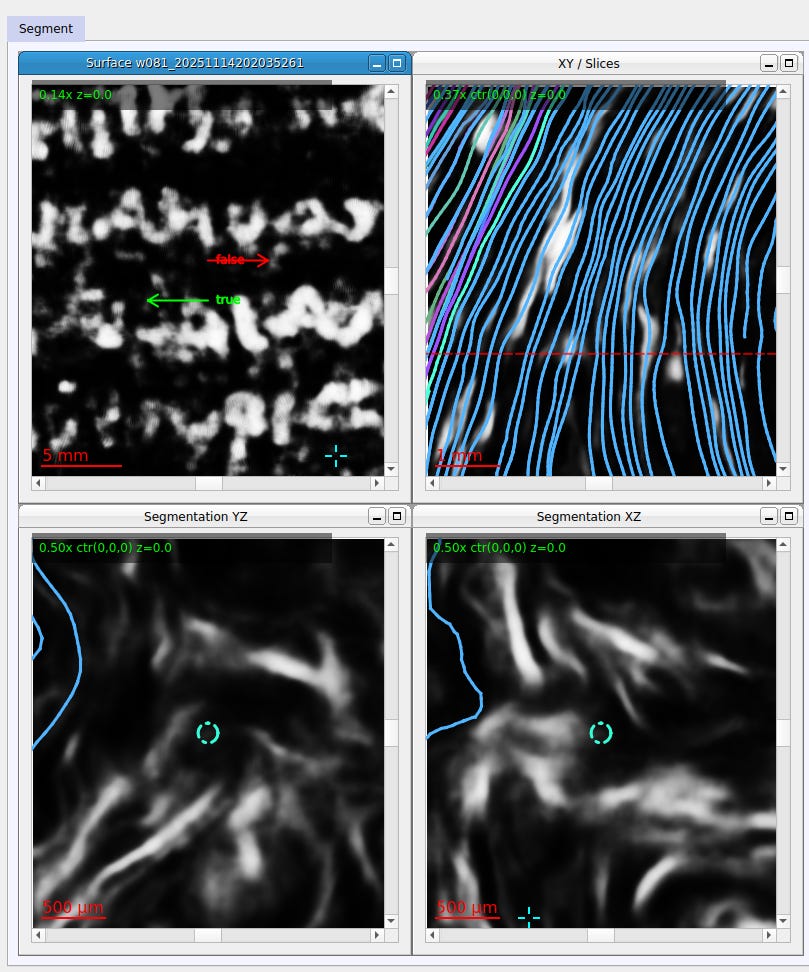
Neural Tracer
A new widget now integrates our full Neural Tracer model. Without using any intermediate representation or binarization of the input surfaces, this neural network looks at the papyrus and automatically outputs part of a mesh! It still does not perform on par with the state of the art, but Paul and Sean found that its training scales well with the size of the dataset. This means that all the unwrapped segments that our team of annotators are generating will be used, at some point, to help this neural tracer surpass the state of the art and move us toward a fully automated pipeline.
Lasagna Optimization
Inspired by the Carnival festivities, Hendrik is developing a semi-global optimization of adjacent wraps in the scroll. Multiple adjacent meshes are linked together like the layers of a lasagna. When
an annotator corrects one, he corrects all of them. This tool is still experimental, but we estimate that when it will be fully functional, it will make annotation at least 3x faster.
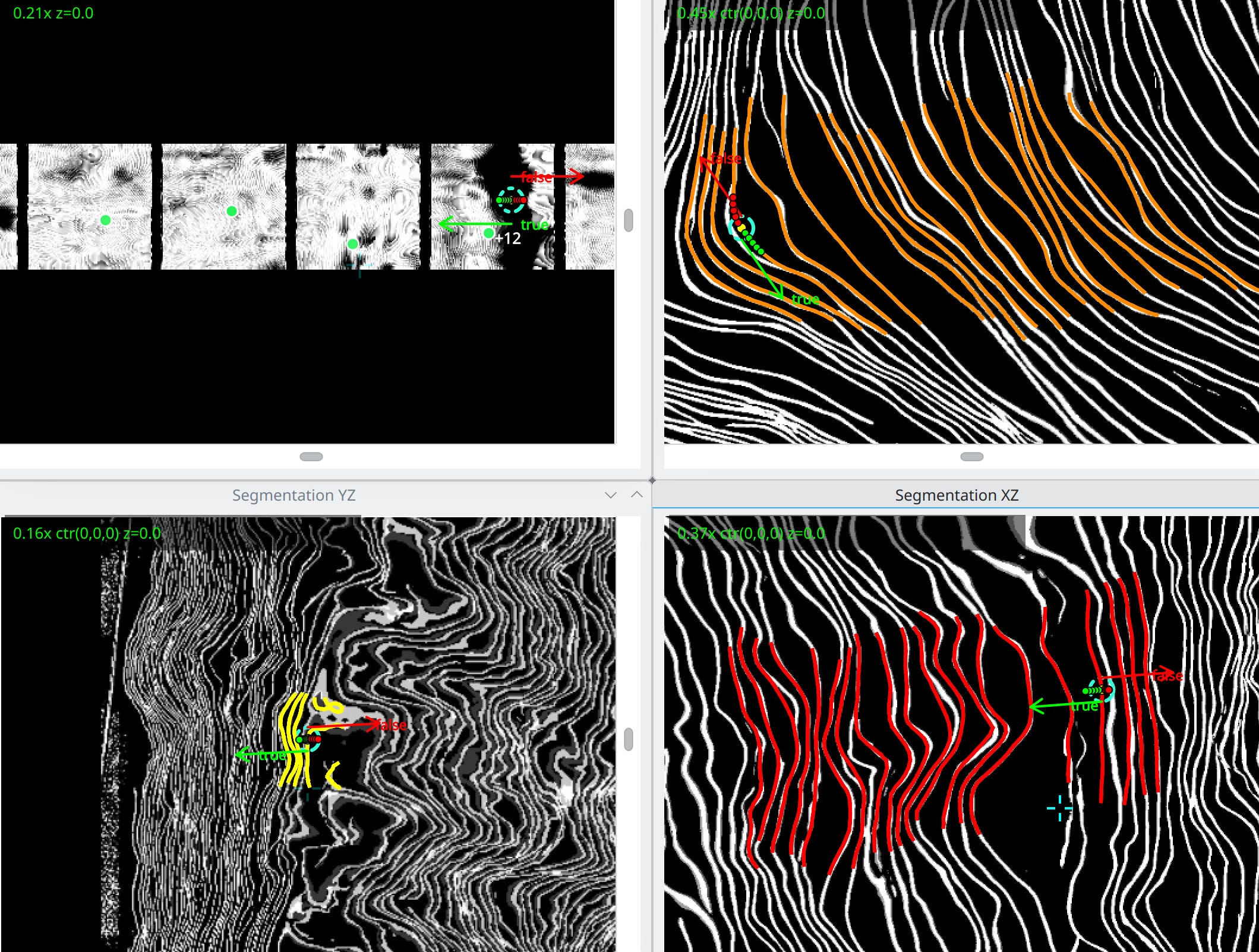
Data availability
AWS Open Data Sponsorship
Our huge dataset of scanned scrolls from Herculaneum will now be hosted for free on the AWS Open Data Program for 2 years! We are really grateful for this partnership, that will allow us to serve our data to billions of people around the world who want to help read the scrolls. Not everything we scanned is there yet, some volumes still need processing, but we are going to host everything through the AWS Open Data Program little by little!
Data Browser
In the wake of the AWS Open Data sponsorship, Johannes redesigned the data page on our website, which now has a beautiful Data Browser page that is programmatically populated with the data served through our repository.
Awarded Progress Prizes
This month, we received 11 submissions.
After carefully reviewing all of them, the team decided to award the following prize:
$ 1,000 (Papyrus)
Our old friend Paul Geiger contributed with a very user-friendly 3D viewer tailored for the Kaggle Surface Detection challenge. The community found it useful, as it was upvoted by 70+ Kaggle competitors, and used by several competitors to post screenshots in Kaggle discussions.
Contribute
Do you want to help us read the scroll? Join our Discord channel and find out how!
Amazing guys. One day you will have an AI that will automatically be able to read any scroll that you scan. Keep up the good work
This is all very exciting to hear about.